

机器学习就是找函数
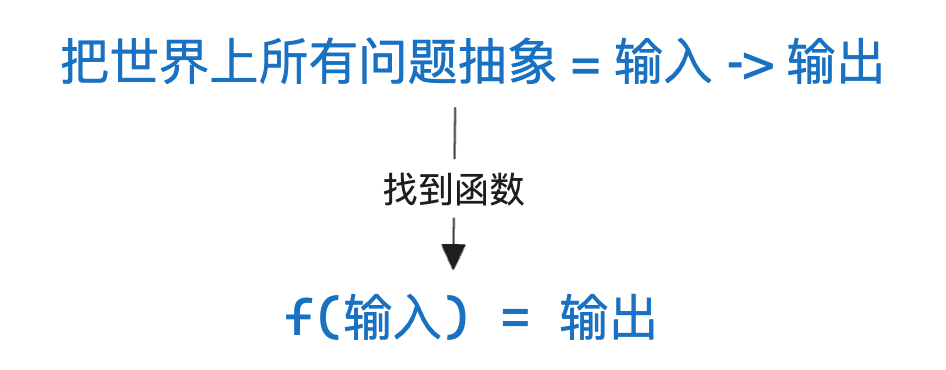
以我对机器学习的理解,认为其本质就是 找函数。我需要从两个角度解释,为什么机器学习就是找函数。
第一个角度,为什么要找函数。因为人解决问题与机器解决问题本质的不同,人能解决问题,但不一定能说清楚背后的原因,而机器解决问题靠的是计算,是可以重复执行且逻辑精确的。所以用机器解决人类解决的问题,也必须找到精确的函数,即便这个函数会非常复杂。
第二个角度,为什么相信能找到函数。我们凭什么认为人类智慧才能完成的任务,可以找到函数解?现实就是 ChatGPT 找到了,所以说明可以找到函数解!也许因为 ChatGPT 背后的神经网络是高维函数,高维函数投影到我们低维的时空能解决所有问题,说明我们被降维打击了。
以上只是一些随口说的感慨,接下来我们进入干货阶段。
假设世间所有问题都抽象为输入、输出
既然我们相信能找到解决一切问题的函数,那这个问题也必须能描述为输入,输出的模式。比如:
- 文字识别:输入图像,输出文字。
- 语音合成:输入语音,输出语音。
- 做题:输入题目,输出答案。
就像知乎的 slogan “有问题就会有答案”,世界上绝大部分需要人类解决的问题,似乎都能通过输入、输出解决。
好,当我们觉得世间所有问题都能抽象为输入输出,那如果我们找到了一个函数,对于每一种输入,结果输出都是人类认可的正确答案,那这个函数不就是一个超级智慧大脑吗?
假设我们发现了一个函数 f(x):
f("小红有3个苹果,给了小明1个,还剩几个?") = "2个"f("我真是谢谢你们的服务,烤冷面外卖送到的时候真成了冷面。这句话是正面还是负面评价?") = "负面"
那就认为,对这两个例子来说,函数 f(x) 就是机器学习要找的函数。
那么难点来了,怎么找到这个函数呢?
如何找到这个完美函数
ChatGPT 几乎已经找到了这个完美函数,它可以几乎解决一切问题,这也是我们学习机器学习的动力。但作为初学者,只盯着火箭是永远也学不会的,让我们先从拧螺丝开始。
我们降低一下目标,把要找的函数设定为 y = 3x,即我们要找一个函数 f(x),f(1) = 3,f(2) = 6,f(10) = 30。
有人会说这不简单吗,y = 3x。嗯,别急,我们此时还不知道答案呢,或者当问题变得非常复杂时,靠人脑根本找不到函数的表达式时,怎么样才能让函数寻找得以继续?
我们必须找到一条通用的路线,让无论这个函数的表达式是什么,都可以通过输入与输出自动寻找,让计算机帮我们自动寻找,哪怕付出非常大的计算代价,这就是机器学习领域说的 “训练模型”(training)。
换句话说,我们设定的方法必须能拓展到任意的输入输出,这样我们才可能训练 f("小红有3个苹果,给了小明1个,还剩几个?") = "2个" 这样的模型,也就是说,这个方法必须仅凭输入输出就可以运作,而不需要依赖任何人类数学知识的干预,这样才可执行。
机器学习最重要的三部曲出现了,它用在寻找 y = 3x 这种函数上看着很蠢,但用在更复杂的函数上,却如神来之笔。
找函数三部曲
机器学习理论最早由 沃伦·麦卡洛克、沃尔特·皮茨 提出,后续大部分贡献都由英国、美国、德国、法国、加拿大等国人推动,所以绝大部分是英文资料,所以我们耳熟能详的关键词都是英文词汇,翻译成中文反而表述或者含义上容易引发歧义,所以为了效率,关键词汇还是写成英文好了。
还是以寻找 y = 3x 为例,假设我们不知道要找的函数 f(x) = 3x,但知道一些零星的输入输出,比如 f(1) = 3,f(2) = 6,f(10) = 30,这些输入输出组合成为 Training data(训练资料)。Training data 是比较好找的,好比想要训练一个判断一个句子是积极还是消极的场景,要直接写出 f(x) 是极其困难的,但举一些正向或者负向的例子确实很容易的,比如:
f("商品很好用") = "积极"f("杯子都碎了") = "消极"f("下次还买") = "积极"
这些输入与输出的组合就是 Training data,找函数三部曲就是仅凭 Training data 就能找到它的实现函数,这就是机器学习的美妙之处。
第一步 define model function
define model function 就是定义函数,这可不是一步到位定义函数,而是定义一个具有任意数量未知参数的函数骨架,我们希望通过调整参数的值来逼近最终正确函数。
假设我们定义一个简单的一元一次函数:
y = b + wx
其中未知参数是 w 和 b,也就是我们假设最终要找的函数可以表示为 b + wx,但具体 w 和 b 的值是多少,是需要寻找的。我们可以这么定义:
const modelFunction = (b: number, w: number) => (x: number) => {
return b + w * x;
};
其中 w 表示 weights(权重),b 表示 bias(偏移),对这个简单的例子比较好理解。这样对于每一组 w 和 b,都能产生一个唯一的函数。
你也许会觉得,一元一次函数根本不可能解决通用问题。对,但为了方便说明机器学习的基本原理,我们把目标也设定为了简单的 y = 3x。
第二步 define loss function
define loss function 就是定义损失函数,这个损失可以理解为距离完美目标函数的差距,可以为负数,越小越好。
我们需要定义 loss 函数来衡量当前 w 与 b 的 loss,这样就可以判断当前参数的好坏程度,才能进入第三步的优化。因此 loss 函数的入参就是第一步 model function 的全部未知参数:w 与 b。
有很多种方法定义 loss 函数,一种最朴素的方法就是均方误差:
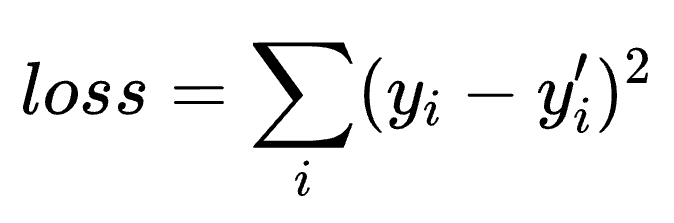
即计算当前实际值 modelFunction(b,w)(x) 与目标值 3x 的平方差。那么 loss 函数可以这样定义:
const lossFunction =
(b: number, w: number) =>
// x 为 training data 输入
// y 为 training data 对应输出
(x: number, y: number) => {
// y',即根据当前参数计算出来的 y 值,函数名用 cy 表示
const cy = modelFunction(b, w)(x);
return Math.pow(y - cy, 2);
};
上述函数在给定 w 与 b 的下,计算在某个 training data 下的 loss,在调用处遍历所有 training data,把所有 loss 加起来,就是所有 training data 的 loss 总和。
为了让寻找的函数更准确,我们需要想办法让 loss 函数的值最小。
第三步 optimization
optimization 就是优化函数的参数,使 loss 函数值最小。
我们再重新梳理一下这三步。第一步定义 model function,包含了 n 个未知参数,第二步定义 loss function,选择比如均方误差的模型,值的计算依赖于 model function,第三步希望找到这 n 个参数的值,使得 loss function 值最小。
因为 loss function 定义就是值越小越贴近要寻找的目标函数,所以最小化 loss function 的过程就是寻找最优解的过程。
而寻找 loss function 的最小值,需要不断更新未知参数,如果把 loss 函数画成一个函数图像,我们想让函数图像向较低的值走,就需要对当前值求偏导,判断参数更新方向:
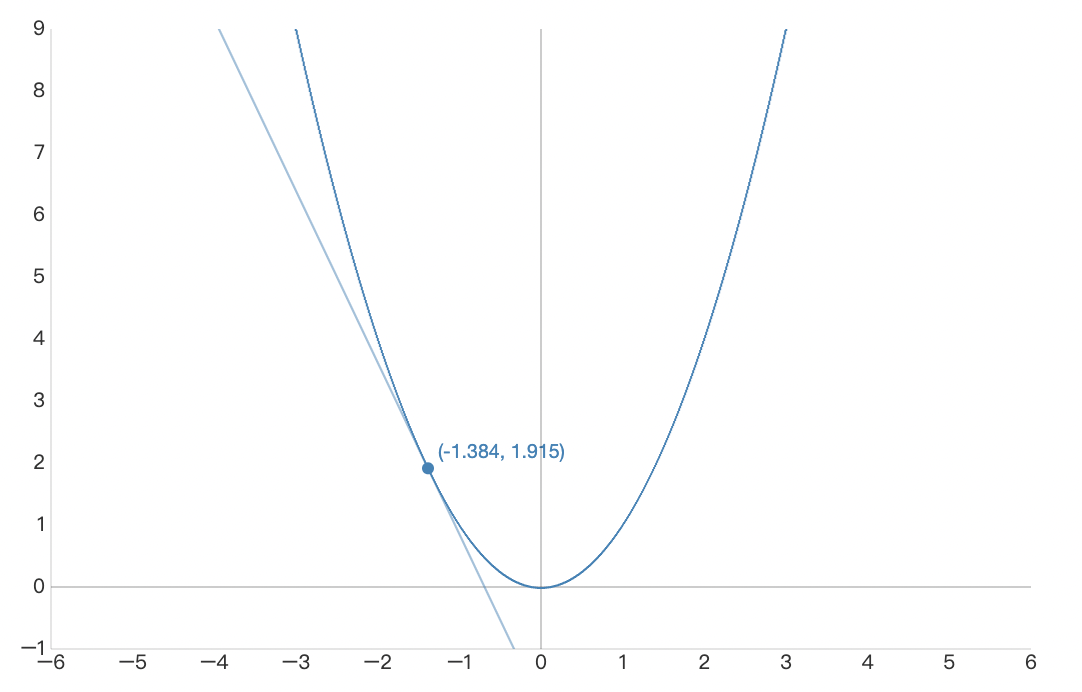
如上图所示,假设上图的 x 轴是参数 w,y 轴是此时所有 training data 得到的 loss 值,那么只要对 loss 函数做 w 的偏导,就能知道 w 要怎么改变,可以让 loss 变得更小(当偏导数为负数时,右移,即 w 增大可以使 loss 减小,反之亦然)。
根据 loss function 的定义,我们可以分别写出 loss function 对参数 b 与 w 的偏导公式:
对 b 偏导:

对 w 偏导:
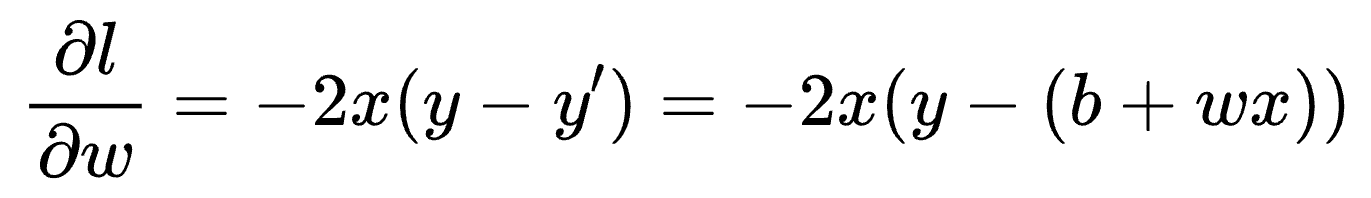
注意,这里仅计算针对某一个 training data 的偏导数,而不用把所有 training data 的偏导数结果加总,因为后续如何利用这些偏导数还有不同的策略。
那么代码如下:
const optimization = (b: number, w: number) => (x: number, y: number) => {
const gradB = -2 * (y - modelFunction(b, w)(x));
const gradW = -2 * x * (y - modelFunction(b, w)(x));
return { gradB, gradW };
};
接着我们就可以使用 training data 开始训练,不断更新参数 w 与 b 的值,直到 loss function 的值下降到极限,就可以认为训练完毕啦。
训练有三种方式使用偏导数,随机梯度下降、批量梯度下降与小批量梯度下降。它们的区别仅在于什么时候真正更新 w 与 b。
- 随机梯度下降:对每一个 training data 项都立刻更新 w 与 b。
- 批量梯度下降: 对所有 training data 都计算出 w 与 b,最后取平均值一次更新,之后再进入下一轮递归。
- 小批量梯度下降:对 training data 取一个 batch size,达到 batch size 后立刻更新 w 与 b。
代码实践
假设我们采用批量梯度下降,training 的过程如下:
细心的你可能发现在 training 过程中,用到了 optimization 与 model function,但没有直接用到 loss function。其实 optimization 的定义取决于 loss function 的形态,因为 optimization 更新参数的逻辑就是对 loss function 求偏导,所以虽然函数调用上没有直接关系,但逻辑上 model function、loss function、optimization 这三者就像齿轮一样紧紧咬合。
以如下 training data 为例,看一下较为直观的训练过程:
// y = 3x
const trainingData = [
[1, 3],
[2, 6],
[3, 9],
[4, 12],
[5, 15],
];
// 初始化 b 和 w 参数
let b = initB;
let w = initW;
// 每次训练
function train() {
let gradBCount = 0;
let gradWCount = 0;
trainingData.forEach((trainingItem) => {
const { gradB, gradW } = optimization(b, w)(
trainingItem[0],
trainingItem[1]
);
gradBCount += gradB;
gradWCount += gradW;
});
b += (-gradBCount / trainingData.length) * learningRate;
w += (-gradWCount / trainingData.length) * learningRate;
}
// 训练 500 次
for (let i = 0; i < 500; i++) {
train()
}
先随机初始化参数 b 与 w,每次训练时,计算参数 b 与 w 在每个训练数据的偏导数,最后按照其平均值更新,更新方向是导数的负数方向,所以 gradCount 前面会加上负号,这样 loss 才能往低处走。learningRate 是学习速率,需要用一些 magic 的方式寻找,否则学习速率太大或者太小都 train 不起来。
把函数寻找过程可视化,就形成了下图:

可以发现,无论初始值参数 b 和 w 怎么选取,最终 loss 收敛时,b 都会趋近于 0,而 w 趋近于 3,即无限接近 y=3x 这个函数。
至此,我们拥有了一个很简单,也很强的机器学习程序,你给它任意 x、y 点作为输入,它就可以找到最为逼近的线性函数解。
总结
作为机器学习的第一课,我们学习了利用 define model function - define loss function - optimization 三部曲寻找任意函数,其中反映出来的是不依赖人类经验,完全依靠输入与输出,让机器探索函数形态的理念。
虽然我们举的 y=3x 例子比较简单,但它可以让我们直观的了解到机器学习是怎么找函数的,我们要能多想一步,设想当函数未知参数达到几十,几百,甚至几千亿个时,靠人类解决不了的问题,这个机器学习三部曲可以解决。
也许你已经发现,我们设定的 y = b + wx 的函数架构太过于简单,它只能解决线性问题,我们只要稍稍修改 training data 让它变成非线性结构,就会发现 loss 小到某一个值后,就再也无法减少了。通过图可以很明显的发现,不是我们的 define loss function 或者 optimization 过程有问题,而是 define model function 定义的函数架构根本就不可能完美匹配 training data:

这种情况称为 model bias,此时我们必须升级 model function 的复杂度,升级复杂度后的函数却很难 train 起来,由此引发了一系列解决问题 - 发现新问题 - 再解决新问题的过程,这也是机器学习的发展史,非常精彩,而且读到这里如果你对接下来的挑战以及怎么解决这些挑战非常感兴趣,你就具备了入门机器学习的基本好奇心,我们下一篇就来介绍,如何定义一个理论上能逼近一切实现的函数。
转自 前端精读微信公众号
Related Issues not found
Please contact @bajiu to initialize the comment