

PyTorch是一个开源的机器学习库,广泛用于计算机视觉和自然语言处理等领域,因其易于学习和使用而受到许多研究者和开发者的青睐。
在开始之前,有几个基本的概念,先了解一下:
深度学习
深度学习是机器学习的一个分支,它通过模拟人脑的工作原理来处理数据和识别模式。深度学习的核心是深度神经网络,这种网络含有多个处理层,可以自动学习数据的高级特征。与传统机器学习相比,深度学习不需要人工设计特征,它能够直接从原始数据中自动学习和提取特征。
神经网络
神经网络由一系列的层构成,每层包含多个神经元。每个神经元接收输入,对输入进行加权求和,然后通过一个激活函数来决定是否将信号传递给下一层。神经网络的基本类型包括:
- 前馈神经网络(Feedforward Neural Networks):数据在这种网络中只向前传递。它们通常用于简单的分类和回归任务。
- 卷积神经网络(Convolutional Neural Networks, CNNs):特别适用于处理图像数据。通过卷积层,CNN能够捕捉到图像中的空间层次结构。
- 循环神经网络(Recurrent Neural Networks, RNNs):适用于处理序列数据,如文本或时间序列数据。RNN能够保持状态(记忆之前的输入),这使得它们在处理连续数据时非常有效。
张量(Tensor)
张量是一个多维数组,是深度学习中处理和存储数据的主要形式。在PyTorch中,张量用于表示输入数据、模型的参数等。张量可以是一个数(0D张量)、一维数组(1D张量)、二维数组(2D张量),或者更高维度的数组。
自动微分(Autograd)
自动微分是深度学习中的一个关键概念,它允许框架自动计算神经网络中参数的梯度。这是通过跟踪计算图和使用链式法则来实现的。在PyTorch中,torch.autograd提供了自动求导的功能,这使得模型训练过程(特别是梯度下降法)变得简单高效。
手写数字识别
这是一个经典的入门级项目,涉及到了数据加载、模型构建、训练和评估的基本流程。
下面是使用PyTorch构建一个简单的神经网络进行手写数字识别的基本步骤:
1.下载并加载数据集:使用torchvision来下载MNIST数据集,并进行基本的预处理(如归一化)。
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False)
2.定义模型结构:使用torch.nn模块定义一个简单的前馈神经网络。
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28*28, 128) # 28*28是图片大小,128是隐层神经元数量
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10) # 10个输出对应10个类别
def forward(self, x):
x = x.view(-1, 28*28) # 展平图片
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x, dim=1)
net = Net()
3.定义损失函数和优化器:
选择损失函数和优化器:对于分类任务,常用的损失函数是交叉熵损失。优化器用于更新模型的权重,常用的有SGD和Adam。
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
4.训练模型:
训练循环:在每个epoch中,模型会遍历训练数据集,计算损失并更新权重。
for epoch in range(10): # 循环遍历数据集多次
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss/len(trainloader)}")
print('Finished Training')
5.评估、生成模型:
- 测试模型:使用测试数据集评估模型性能,计算准确率。
- 生成模型:要将训练好的模型保存为
.pth文件,可以使用PyTorch的torch.save方法。这个方法允许你将模型的状态字典(包含模型参数)保存到一个文件中。未来,你可以通过加载这个状态字典来重建或使用这个模型,而不需要重新训练。
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct / total}%')
# 保存模型状态
torch.save(net.state_dict(), 'model.pth')
print('Saved model to model.pth')
6.使用模型
# 加载模型状态
model = Net()
model.load_state_dict(torch.load('model.pth'))
model.eval()
# 预测函数
def predict_image(image_path, model):
image = Image.open(image_path)
transform = transforms.Compose([
transforms.Resize((28, 28)),
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
image = transform(image).unsqueeze(0) # 添加一个批次维度
with torch.no_grad():
outputs = model(image)
_, predicted = torch.max(outputs, 1)
return predicted.item()
代码
# 定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128) # 28*28是图片大小,128是隐层神经元数量
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10) # 10个输出对应10个类别
def forward(self, x):
x = x.view(-1, 28 * 28)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x, dim=1)
# 实例化模型
net = Net()
def main():
# 第一步:加载和预处理数据
# 数据转换:将图片转换为Tensor,并标准化
transform = transforms.Compose([
# 将图像转换为 PyTorch 张量
transforms.ToTensor(),
# 标准化处理
transforms.Normalize((0.5,), (0.5,))
])
# 加载训练数据集
trainset = MNIST(root='../Data', train=True,
download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
# 加载测试数据集
testset = MNIST(root='../Data', train=False,
download=True, transform=transform)
testloader = DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
# 第二步:定义神经网络结构
# 实例化模型
# net = Net()
# 第三步:定义损失函数和优化器
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器, 使用随机梯度下降法
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 第四步:训练模型
epochs = 15
for epoch in range(epochs):
running_loss = 0
for images, labels in trainloader:
optimizer.zero_grad() # 清零梯度
output = net(images) # 前向传播
loss = criterion(output, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新权重
running_loss += loss.item()
else:
print(f"Epoch {epoch + 1}/{epochs} - Training loss: {running_loss / len(trainloader)}")
# 第五步:测试模型
correct = 0
total = 0
with torch.no_grad(): # 在评估模式下,不计算梯度
for images, labels in testloader:
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct / total}%')
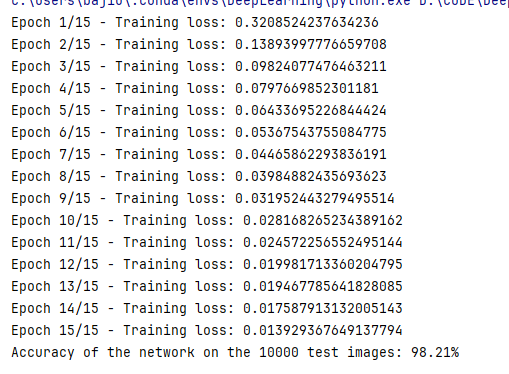
然后再用生成后的模型进行预测
# 使用训练好的模型进行预测
def predict_image(image_path):
image = Image.open(image_path)
# 定义转换操作,包括缩放、转为灰度、转为Tensor、归一化
transform = transforms.Compose([
transforms.Resize((28, 28)), # 将图片缩放到28x28
transforms.Grayscale(num_output_channels=1), # 转换为单通道灰度图
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize((0.5,), (0.5,)) # 归一化
])
# 添加一个批次维度,因为PyTorch模型期望的输入是批次形式
image = transform(image).unsqueeze(0)
# 加载模型状态
model = Net()
model.load_state_dict(torch.load('./model.pth'))
model.eval()
with torch.no_grad():
outputs = model(image)
_, predicted = torch.max(outputs, 1)
print(f"Predicted digit: {predicted.item()}")
return predicted.item()
