

ONNX 是什么?
ONNX(Open Neural Network Exchange)是一种开放的、基于 Protocol Buffers 序列化的模型交换格式和中间表示(IR)。它把深度学习/机器学习模型抽象成一张有向无环图(DAG):
在软件工程中,部署指把开发完毕的软件投入使用的过程,包括环境配置、软件安装等步骤。类似地,对于深度学习模型来说,模型部署指让训练好的模型在特定环境中运行的过程。相比于软件部署,模型部署会面临更多的难题:
- 运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。
- 深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求,模型的运行效率需要优化
因为这些难题的存在,模型部署不能靠简单的环境配置与安装完成。经过工业界和学术界数年的探索,模型部署有了一条流行的流水线:
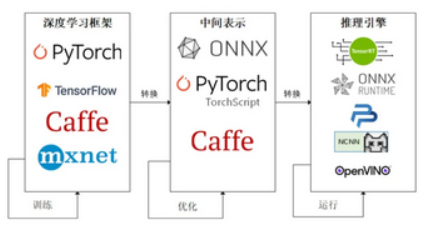
为了让模型最终能够部署到某一环境上,开发者们可以使用任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。之后,模型的结构和参数会被转换成一种只描述网络结构的中间表示,一些针对网络结构的优化会在中间表示上进行。最后,用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写,能高效执行深度学习网络中算子的推理引擎会把中间表示转换成特定的文件格式,并在对应硬件平台上高效运行模型,比如中间表示ONNX转换支持华为芯片推理的OM文件。
ONNX介绍
ONNX (Open Neural Network Exchange)是 Facebook 和微软在2017年共同发布的,用于标准描述计算图的一种格式。目前,在数家机构的共同维护下,ONNX 已经对接了多种深度学习框架和多种推理引擎。因此,ONNX 被当成了深度学习框架到推理引擎的桥梁,就像编译器的中间语言一样。由于各框架兼容性不一,我们通常只用 ONNX 表示更容易部署的静态图。
如下ONNX网络图:

- 输入节点名称:
input - 输出节点名称:
values - 算子节点:
Conv、Sigmoid、Mul - 箭头则表示网络图为有向无环图
ONNX Runtime
基于 ONNX 开放式模型格式,ONNX Runtime 的目的是让不同的机器学习和深度学习框架(如 PyTorch、TensorFlow 和 scikit-learn)训练出的模型能够无缝地部署到生产中。ONNX Runtime 的主要特点有:
- 跨平台支持:包括 Windows、Linux 和 macOS,同时也支持多种硬件架构,如 x86、ARM 和 GPU。
- 高性能:针对多种硬件进行了优化,目的是在不同设备上提供低延迟和高吞吐量。
- 灵活性:可以轻松集成到多种应用和服务中,包括云服务、边缘设备和嵌入式系统。
- 框架兼容性:ONNX Runtime 支持通过各种深度学习框架创建的模型,这些模型可以转换为 ONNX 格式并在 ONNX Runtime 中执行。
- 硬件加速器支持:支持 NVIDIA 的 CUDA、TensorRT、AMD 的 ROCm、Intel 的 MKL-DNN/OpenVINO 等硬件加速器,以优化模型的推理性能。
- 社区支持:由于微软的背书以及社区贡献,ONNX Runtime 拥有一个活跃的开发者社区,不断更新和改进。
- 训练:除了高性能的推理能力,ONNX Runtime 从1.2 以后也开始支持训练,并且能加速训练。
ONNX Runtime 支持多种编程语言:
- **C++**:ONNX Runtime 原生就是用 C++编写的,如果应用对性能敏感,可以直接调用。
- Python:Python API 允许加载 ONNX 模型,可以在不同的计算设备(如CPU, GPU)上运行模型,是被使用最多的语言。
- **C#**:C#的API,使 .NET开发者能够在应用程序中轻松地集成和使用 ONNX 模型。
- JavaScript:JavaScript 库允许在浏览器和 Node.js 环境中运行 ONNX 模型,使得在Web应用程序中部署机器学习模型变得更加容易。
另外还有 Java WinRT Objective-C Ruby Julia 等语言的支持,覆盖面非常广。
Web 推理引擎
Web 推理除了算力基础的支持,还依赖对应生态下的推理引擎的支持。这些推理引擎主要负责加载相应的模型文件,并输入数据进行推理计算,一些框架不仅提供了推理的能力,也提供了模型训练上的支持。
目前大部分推理引擎对 Web算力的利用上,都集中在 WebAssembly 和 WebGL 的支持,仅有 Tensorflow.js、WebDNN和 TVM 提供了对 WebGPU 的试验性支持。
Tensorflow.js
由 Google 推出,提供 Tensorflow 生态内的模型训练和推理。支持 GPU 硬件加速。在 Node.js 环境中,如果有 CUDA 环境支持,或者在浏览器环境中,有 WebGL 环境支持,TensorFlow.js 可以使用硬件进行加速。
ONNX Runtime Web
ONNX(Open Neural Network Exchange),是微软、Facebook、亚马逊等提出用来表示深度学习模型的开放格式。所谓开放就是 ONNX 定义了一组和环境、平台均无关的标准格式,来增强各种机器学习模型的可交互性ONNX 的理念是通过统一的算子集 (Op Set)来对不同框架产生的模型进行表示。
ONNX 基本支持了主流深度学习的框架:
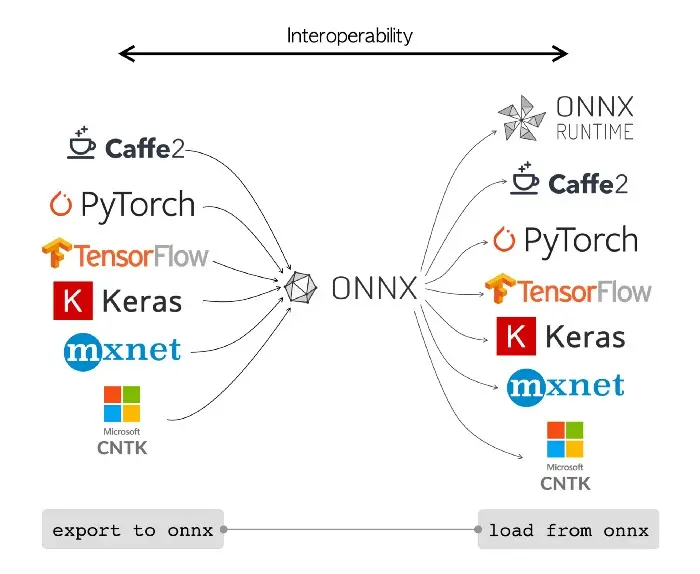
ONNX Runtime 是将统一的 onnx 模型包运行起来,对 ONNX 模型进行解读、优化、运行。
ONNX Runtime 支持多种运行后端包括 CPU,GPU,TensorRT,DML等。
ONNX Runtime Web是微软推出的 ONNX 模型的 Web 推理库,它支持 wasm 和 webgl 的推理。之前旧版本是 onnx.js,但目前已经全部迁移到 ONNX Runtime Web
ONNX Runtime API
使用 ONNX Runtime 的一般步骤如下:
- 模型转换:使用相应的深度学习框架将训练好的模型导出为 ONNX 格式。
- 模型加载:在 ONNX Runtime 中加载转换好的 ONNX 模型。
- 数据准备:准备输入数据并将其转换为适合模型的格式。
- 模型推理:使用 ONNX Runtime 执行模型推理,并获取输出结果。
- 结果处理:处理模型推理的输出结果,如分类、回归或其他类型的机器学习任务。
1、InferenceSession
InferenceSession 是 ONNX Runtime 库中的一个核心类,用于运行 ONNX 模型的推理。它封装了加载模型、配置会话选项、运行推理以及管理模型输入和输出的所有细节。InferenceSession 提供了高效、方便的接口,使得进行模型推理变得简单,无需关心底层硬件或执行提供者的复杂性。
2、Tensor
在 ONNX Runtime 中,Tensor 是一种基本的数据结构,用来表示模型的输入、输出以及各层之间传递的数据。它是一个多维数组,类似于 NumPy 中的 ndarray 或 PyTorch 中的 tensor。Tensor 可以包含不同类型的数值数据,如整数、浮点数等,并且可以有不同的形状,即不同的维度和大小。
3、Env
Env 用来表示 ONNX Runtime 的全局状态和配置。这个环境对象包含了日志、线程池以及其他全局设置,通常在执行 ONNX 模型前,通常第一步就是创建一个环境实例。创建多个环境可能会导致资源浪费和性能下降。
- 日志记录:环境对象负责配置和控制 ONNX Runtime 的日志记录行为。
- 线程池和并行计算:环境可以用来配置全局线程池的大小和行为,这对于优化模型的执行性能非常重要。
- 资源管理:环境在ONNX Runtime内部用于管理全局资源,确保资源的正确分配和释放。
4、TrainingSession
ONNX Runtime 主要用于模型推理,但仍然提供了一个有限的实验性功能集 ONNX Runtime Training ,用于执行如微调等训练任务。通过扩展 ONNX Runtime 推理引擎来支持训练运算符和梯度计算实现训练优化。ONNX Runtime Training 主要用于在大规模分布式环境中进行模型的微调和优化。这些特性可能仍然是实验性的,并非主流用途。
ONNX Runtime 三个运行阶段
ONNX Runtime 在处理机器学习模型时可以分为三个阶段,Session 构造,模型加载与初始化和推理。
1、Session 构造
创建一个InferenceSession 对象,并初始化 Session 的各个成员,包括负责操作内核管理的对象,负责 Session 配置信息的对象,负责图分割和优化的对象、负责 log 管理的对象等。
2、模型加载与初始化
- 加载
ONNX模型到InferenceSession中 - 解析模型中的图数据结构,包括节点和边,以及模型的参数和权重
- 图优化,减少计算量和内存使用,提高模型运行效率,主要优化有:
- 常量折叠:计算图中的常量表达式,并将其替换为具体的值。
- 操作符融合:将多个操作符融合成一个复合操作符,减少运行时的操作次数。
- 消除无用的节点:移除图中不影响输出的节点。
- 布局优化:改变数据的存储布局以提高存取效率。
3、模型推理
ONNX Runtime 根据优化后的模型图执行计算任务,处理输入数据,并产生输出结果。推理过程可能会利用特定硬件加速器来提高计算效率。ONNX Runtime 支持多种硬件平台和优化路径,包括 CPU、CUDA(GPU)、TensorRT 等,保证在不同的设备和环境中都能获得优异的性能。