

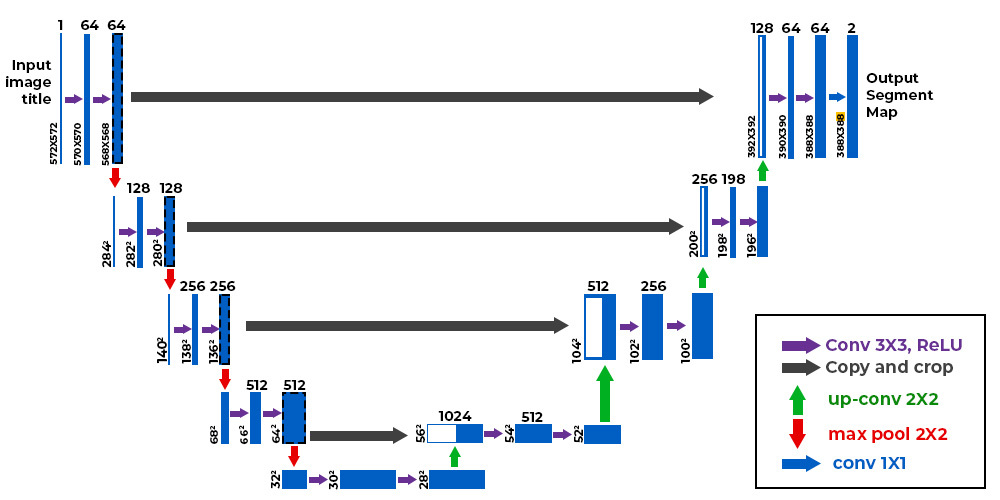
U-Net 的整体结构
U-Net的本质: 一个基于全卷积网络(Fully Convolutional Network, FCN)的对称编解码结构(Encoder-Decoder)的图像分割网络。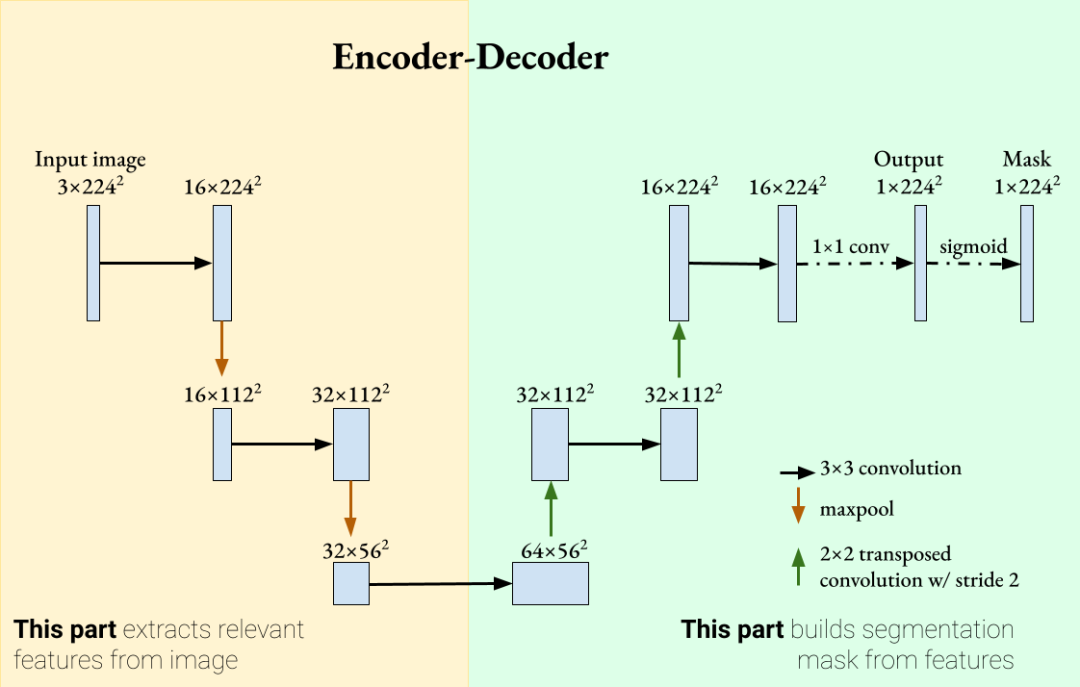
U-Net 有两个主要部分:
- 编码器(Encoder)/压缩路径:
- 解码器(Decoder)/扩展路径:
中间通过一个”桥接层(Bottleneck)“相连。
编码器:提取特征
- 每一层包括:
- 两个卷积层(Conv2D + ReLU)
- 一个最大池化层(MaxPooling),用于降维和提取高级语义特征
- 每下采样一层,通道数增加一倍(比如从 64 → 128 → 256)
作用是:提取图像的特征,但分辨率逐渐减小
解码器:还原空间信息
- 每一层包括:
- 上采样(通常是反卷积或上采样)
- 卷积层(Conv2D + ReLU)
- 与编码器对应层的特征图连接(Skip Connection)
- 每上采样一层,通道数减半(比如从 512 → 256 → 128)
作用是:逐步恢复图像的空间结构
跳跃连接(Skip Connections)
- 把编码器中的中间特征图拼接到解码器中对应层
- 解决特征图分辨率低导致信息丢失的问题
输出层
- 通常是一个 1×1 卷积层,将通道数变成类别数(比如二分类变成1)
- 输出是一个像素级的分割图(mask)
U-Net 的优点
- 不需要大量数据也能训练良好(因为它使用了大量的数据增强和对称结构)
- 精度高,尤其适合医学图像等对边界敏感的应用
- 结构直观清晰,容易修改为变种结构
为了解决不同问题,U-Net 有很多改进版本,比如:
- **U-Net++**:改进跳跃连接,增加了嵌套结构
- Attention U-Net:引入注意力机制,关注更重要区域
- 3D U-Net:用于三维医学图像(如MRI体积数据)
- ResUNet:在
U-Net基础上引入残差连接(ResNet思想)
U-Net 和 CNN 的关系
- 传统CNN是对图像进行分类,输出的结果是整个图像的类标签;UNet是像素级分类,输出的结果是每个像素点的类被,且不同类别的像素会显示不同的颜色。
- 传统CNN是通过卷积层和池化层提取图像特征,经反向传播确定最终参数,并得到最终的特征;而UNet的特征提取步骤较为复杂,分为Encoder和Decoder。
举个例子
用 CamVid 数据集 ,训练一个 U-Net 来实现像素级分割。
图像中的每个像素划分为“天空”、“建筑物”、“行人”等语义类别。
第一步:导入依赖和设置设备
# 引入必要的库
import os # 文件路径操作
import numpy as np # 数值计算
from PIL import Image # 图像读取和处理
import torch # PyTorch 主库
from torch import nn, optim # 神经网络模块和优化器
from torch.utils.data import Dataset, DataLoader # 自定义数据集和批处理
import torchvision.transforms as T # 图像预处理变换
import requests, zipfile # 下载和解压 CamVid 数据集
from tqdm import tqdm # 进度条
import matplotlib.pyplot as plt # 图像可视化
# 选择训练设备,优先使用 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
第二步:下载和解压 CamVid 数据集
# GitHub 上的数据集地址
url = "https://github.com/alexgkendall/SegNet-Tutorial/archive/refs/heads/master.zip"
filename = "camvid.zip"
# 如果本地没有压缩文件,则下载
if not os.path.exists("camvid.zip"):
print("📥 正在下载CamVid数据集...")
response = requests.get(url, stream=True)
with open(filename, "wb") as f:
for chunk in tqdm(response.iter_content(1024)): # 每次写入 1024 字节
f.write(chunk)
# 解压并重命名子目录,统一命名
if not os.path.exists("CamVid"):
with zipfile.ZipFile(filename, "r") as zip_ref:
zip_ref.extractall()
os.rename("SegNet-Tutorial-master/CamVid", "CamVid")
os.rename("CamVid/trainannot", "CamVid/train_labels") # 标签文件夹重命名
os.rename("CamVid/testannot", "CamVid/test_labels")
os.rename("CamVid/valannot", "CamVid/val_labels")
- 下载并解压 GitHub 上的原始 CamVid 数据集。
- 重命名标注文件夹,方便后续使用。
第三步:自定义数据集类 CamVidDataset
# 自定义数据集类
class CamVidDataset(Dataset):
def __init__(self, image_dir, label_dir, transform=None):
self.image_dir = image_dir # 图片文件夹路径
self.label_dir = label_dir # 标签文件夹路径
self.images = sorted(os.listdir(image_dir)) # 读取图片文件名
self.labels = sorted(os.listdir(label_dir)) # 读取标签文件名
self.transform = transform # 图像预处理函数
# 标签颜色与类别 ID 的映射关系
self.label_map = {
(128, 128, 128): 0, # 天空
(128, 0, 0): 1, # 建筑
(192, 192, 128): 2, # 树
(128, 64, 128): 3, # 道路
(0, 0, 192): 4, # 人行道
(128, 128, 0): 5, # 汽车
(192, 128, 128): 6, # 物体
(64, 64, 128): 7, # 标志
(64, 0, 128): 8, # 栏杆
(64, 64, 0): 9, # 摩托车
(0, 128, 192): 10 # 骑自行车的人
}
def __len__(self):
return len(self.images) # 返回图片总数
def __getitem__(self, idx):
# 加载图像与标签路径
img_path = os.path.join(self.image_dir, self.images[idx])
label_path = os.path.join(self.label_dir, self.labels[idx])
# 加载为 RGB 图像
image = Image.open(img_path).convert("RGB")
label = Image.open(label_path).convert("RGB")
if self.transform:
image = self.transform(image) # 对图像做 resize + ToTensor
# 对标签图进行大小调整(避免尺寸不一致)
label = label.resize((256, 256), Image.NEAREST)
label = np.array(label)
# 创建空白 mask,每个像素对应类别 ID
mask = np.zeros((256, 256), dtype=np.int64)
for rgb, class_id in self.label_map.items():
mask[(label == rgb).all(axis=-1)] = class_id # 匹配颜色并赋值类别编号
return image, torch.tensor(mask, dtype=torch.long)
第四步:定义 U-Net 模型
# U-Net 主体结构
class UNet(nn.Module):
def __init__(self, num_classes=11):
super().__init__()
# 卷积模块(两次卷积 + ReLU)
def conv_block(in_ch, out_ch):
return nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.ReLU(inplace=True)
)
# 编码器部分(下采样)
self.enc1 = conv_block(3, 64)
self.pool1 = nn.MaxPool2d(2)
self.enc2 = conv_block(64, 128)
self.pool2 = nn.MaxPool2d(2)
self.enc3 = conv_block(128, 256)
self.pool3 = nn.MaxPool2d(2)
self.enc4 = conv_block(256, 512)
self.pool4 = nn.MaxPool2d(2)
# 中间的瓶颈部分
self.bottleneck = conv_block(512, 1024)
# 解码器部分(上采样 + 拼接)
self.upconv4 = nn.ConvTranspose2d(1024, 512, 2, stride=2)
self.dec4 = conv_block(1024, 512)
self.upconv3 = nn.ConvTranspose2d(512, 256, 2, stride=2)
self.dec3 = conv_block(512, 256)
self.upconv2 = nn.ConvTranspose2d(256, 128, 2, stride=2)
self.dec2 = conv_block(256, 128)
self.upconv1 = nn.ConvTranspose2d(128, 64, 2, stride=2)
self.dec1 = conv_block(128, 64)
# 最后一层:输出类别个数的通道(像素级分类)
self.final = nn.Conv2d(64, num_classes, 1)
def forward(self, x):
# 编码器过程
e1 = self.enc1(x)
e2 = self.enc2(self.pool1(e1))
e3 = self.enc3(self.pool2(e2))
e4 = self.enc4(self.pool3(e3))
# 瓶颈
b = self.bottleneck(self.pool4(e4))
# 解码器 + skip connection
d4 = self.dec4(torch.cat([self.upconv4(b), e4], dim=1))
d3 = self.dec3(torch.cat([self.upconv3(d4), e3], dim=1))
d2 = self.dec2(torch.cat([self.upconv2(d3), e2], dim=1))
d1 = self.dec1(torch.cat([self.upconv1(d2), e1], dim=1))
# 输出预测图(每个像素属于哪个类别)
return self.final(d1)
第五步:准备数据与模型
# 图像变换(缩放 + 张量转换)
transform = T.Compose([
T.Resize((256, 256)),
T.ToTensor()
])
# 加载训练与验证数据
train_dataset = CamVidDataset("CamVid/train", "CamVid/train_labels", transform=transform)
val_dataset = CamVidDataset("CamVid/val", "CamVid/val_labels", transform=transform)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=4)
# 实例化模型与损失函数、优化器
model = UNet().to(device)
criterion = nn.CrossEntropyLoss() # 多分类损失函数
optimizer = optim.Adam(model.parameters(), lr=1e-3)
第六步:训练函数
# 定义单轮训练过程
def train_one_epoch():
model.train()
total_loss = 0
for images, masks in train_loader:
images, masks = images.to(device), masks.to(device)
outputs = model(images)
loss = criterion(outputs, masks)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_loader)
# 开始训练
for epoch in range(1, 6):
loss = train_one_epoch()
print(f"Epoch {epoch}, Loss: {loss:.4f}")
第七步:可视化输出
model.eval()
with torch.no_grad():
for images, masks in val_loader:
images = images.to(device)
outputs = model(images)
preds = outputs.argmax(dim=1).cpu()
break # 只看一批
# 显示
for i in range(4):
plt.subplot(3, 4, i+1)
plt.imshow(images[i].cpu().permute(1,2,0))
plt.title("Image")
plt.axis("off")
plt.subplot(3, 4, i+5)
plt.imshow(masks[i])
plt.title("GT Mask")
plt.axis("off")
plt.subplot(3, 4, i+9)
plt.imshow(preds[i])
plt.title("Pred")
plt.axis("off")
plt.tight_layout()
plt.show()
loss有问题,未完待续…